What happens when we visit a website in a web browser? To the user a web page opens up in a few seconds depending on the size of web page content, but behind the scenes different components of the web or internet work together to load that particular web page in the browser.
In this series we will explore how a web request is navigated across the internet and fulfilled by the web application hosted in different infrastructures. For simplicity we will consider a monolithic application architecture.
Series Articles
Web Application Architecture vs Infrastructure
In simple terms the application architecture refers to the framework and principles in which the application components collaborate to perform the intended function.
Types of application architectures:
- Monolithic
- Client-Server
- Microservices
- Server less
- Progress Web App
Application infrastructure is the underlying hardware and software components that enables the system to function. This include load balancers, firewalls, servers, and VMs etc.
Web Application Monolithic Architecture
Monolithic application architecture defines a web application as a single unit, i.e. the user interface, business logic and data access are tightly coupled in a single code base. e.g. WordPress
Web Application Infrastructure
In order for a web application to serve its users, it must be deployed on a server accessible via the internet. The very basic setup required for such applications include:
- Server or a VM with web server (Apache or Nginx) installed
- Public IP (IPv4 for simplicity)
- Router & Firewall
The infrastructure diagram is depicted below:
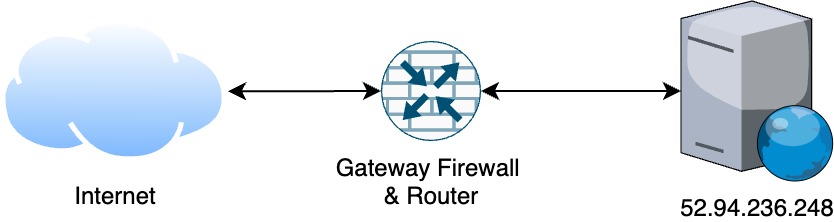
Web Request Cycle
When a user types in a URL (Uniform Resource Locator) in their web browsers the web browser loads that particular resource after a series of communication with the components on the internet. The whole process is carried out in steps:
Step 1: URL typed in web browser
The first step in the chain is to open up a web browser such as Google Chrome, Mozilla Firefox, Safari, and Microsoft Edge and type in the URL such as https://amazon.com.
The URL consists of a protocol (https://) and a domain name (amazon.com) also called a fully qualified domain name (FQDN). Often, URLs will have www in them which is a sub-domain and references the deprecated phrase “World Wide Web” popular in 1990s.
Step 2: Name Resolution Through Domain Name Server (DNS)
Machines are identified by their IPs in a network. IP (Internet Protocol) is an address either v4 (32-bit numeric) or v6 (128 bit hexadecimal) that provide identification to any network device capable of communication on Layer-3 of the OSI or TCP/IP stack. Thus, to access a web application, we require the IP address of the server it is hosted on. In the case of https://amazon.com the IP address can be acquired by using a tool called ping, which is 52.94.236.248 as shown:
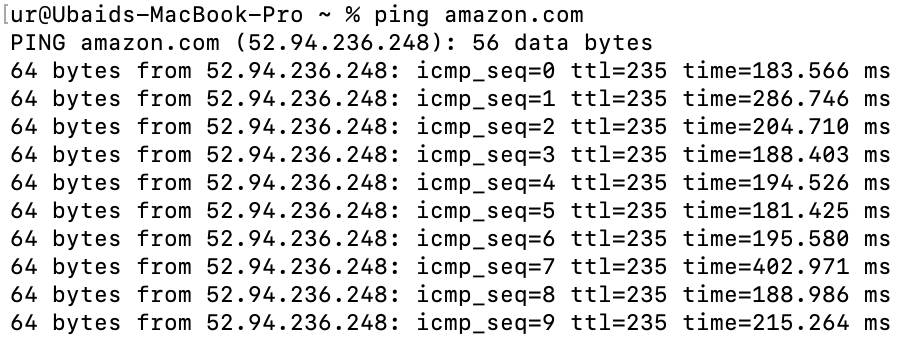
Accessing a web application or website through IP makes memorization difficult. To overcome this problem domain names are used to identify Internet resources, with a text-based label that is easier to memorize than the numerical or hexadecimal addresses used in the Internet protocols.
Domain Name Server (DNS) is used to map the text-based label to the IP. The root / authoritative DNS contains all the registered domain names. The first-level set of domain names are the top-level domains (TLDs), including the generic top-level domains (gTLDs), such as the prominent domains com, info, net, edu, and org, and the country code top-level domains (ccTLDs).
DNS entries are cached at different levels in the network such as ISPs, organization DNS, routers and OS for faster resolution. At first, the DNS cache maintained by the browser is checked, if an entry does not exist, next the gateway router or closest DNS, if fails, next the ISP DNS so on and so forth until the root DNS.
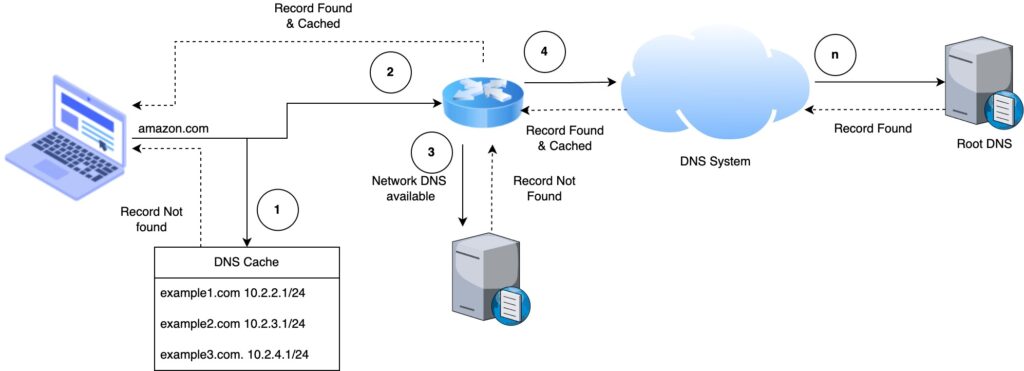
In order to make the resolution direct we can enter public DNS available in OS network configuration. Public DNS provided by Google are 8.8.8.8 and 8.8.4.4
Once the domain name is resolved the browser receives an IP for the resource.
Step 3: Transport Control Protocol (TCP)
The OS initiate a TCP connection with the server. The connection is established using a three-way handshake.
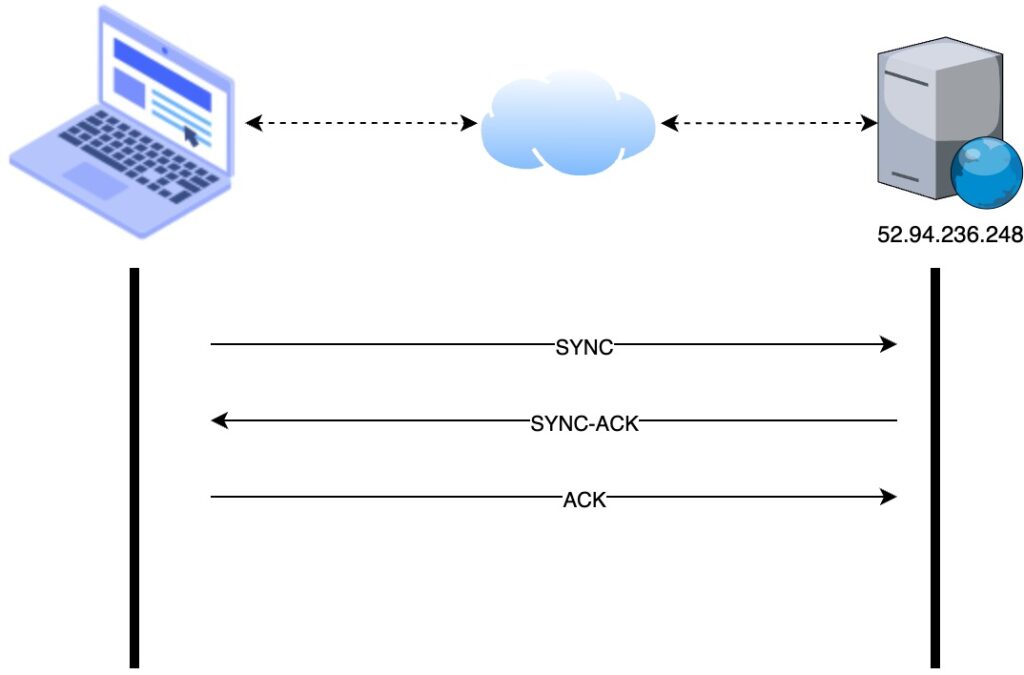
- The SYNC message is sent from the user device to the server
- The server responds with an acknowledgement (SYNC-ACK) message that the message has been received
- The user device responds with an acknowledgement (ACK) message informing the server that it had received the acknowledgement sent by it.
At this stage the connection has been established and data can transmit between the two parties.
Step 4: Hypertext Transfer Protocol (HTTP)
Web application data is communicated using the application layer protocol referred to as HTTP. The browser sends a GET request to the server requesting the resource from the web server. In that request the browser adds its identifier in the packet header called user-agent. The value can be used to present a specialized web page for that device. e.g. a web browser on mobile phone can have a different layout than a desktop one.
Step 5: Web server response
The web server (Apache or Nginx) accepts the request, a back-end programming language or framework (PHP, Ruby, Python) decides what content to send, generates or loads that content and sends the response in HTML (Hypertext Markup Language) as shown:
<!DOCTYPE html>
<html>
<head>
<!-- head definitions go here -->
</head>
<body>
<!-- the content goes here -->
</body>
</html>Step 6: Browser renders the content
The response content is only text and the browser responsibility is to render the text into a proper format. The browser reads the response line by line and start loading other resources i.e. static files such as media, scripts and styles.
Upon downloading static files the browser applies styling and runs the JavaScript linked to the page and the result looks as shown
Leave a Reply